文章来源
文章来源: [1907.12412] ERNIE 2.0: A Continual Pre-training Framework for Language Understanding
CODE:https://github.com/PaddlePaddle/ERNIE
Introduction
Motivation
Generally the pre-training of models often train the model based on the co-occurrence of words and sentences. While in fact, there are other lexical, syntactic and semantic information worth examining in training corpora other than cooccurrence. For example, named entities like person names, location names, and organization names, may contain conceptual information. Information like sentence order and sentence proximity enables the models to learn structure aware representations. And semantic similarity at the document level or discourse relations among sentences allow the models to learn semantic-aware representations. In order to discover all valuable information in training corpora, be it lexical, syntactic or semantic representations, we propose a continual pre-training framework named ERNIE 2.0
To sum up: from co-occurrence of words and sentences to lexical(named entities), syntactic (sentence order and proximity) and semantic information(semantic similarity at the document level or discourse relations)
ERNIE 2.0
Our ERNIE framework supports the introduction of various customized tasks continually, which is realized through continual multi-task learning. When given one or more new tasks, the continual multi-task learning method simultaneously trains the newly-introduced tasks together with the original tasks in an efficient way, without forgetting previously learned knowledge. In this way, our framework can incrementally train the distributed representations based on the previously trained parameters that it grasped. Moreover, in this framework, all the tasks share the same encoding networks, thus making the encoding of lexical, syntactic and semantic information across different tasks possible.
The ERNIE 2.0 Framework
it could constantly introduce a large variety of pretraining tasks to help the model efficiently learn the lexical, syntactic and semantic representations. Based on this, ERNIE 2.0 framework keeps updating the pre-trained model with continual multi-task learning. During fine-tuning, the ERNIE model is first initialized with the pre-trained parameters, and would be later fine-tuned using data from specific tasks.
Continual Pre-training
The process of continual pre-training contains two steps. Firstly, We continually construct unsupervised pre-training tasks with big data and prior knowledge involved. Secondly, We incrementally update the ERNIE model via continual multi-task learning.
Pre-training Tasks Construction
We can construct different kinds of tasks at each time, including word-aware tasks,structure-aware tasks and semantic-aware tasks. All of these pre-training tasks rely on self-supervised or weak-supervised signals that could be obtained from massive data without human annotation. Prior knowledge such as named entities, phrases and discourse relations is used to generate labels from large-scale data
Continual Multi-task Learning
The ERNIE 2.0 framework aims to learn lexical, syntactic and semantic information from a number of different tasks. Thus there are two main challenges to overcome.
- ①The first is how to train the tasks in a continual way without forgetting the knowledge learned before.
- ②The second is how to pre-train these tasks in an efficient way
We propose a continual multi-task learning method to tackle with these two problems. ①Whenever a new task comes, the continual multi-task learning method first uses the previously learned parameters to initialize the model, and then train the newly-introduced task together with the original tasks simultaneously. ②We solve this problem by allocating each task N training iterations. Our framework needs to automatically assign these N iterations for each task to different stages of training. In this way, we can guarantee the efficiency of our method without forgetting the previously trained knowledge
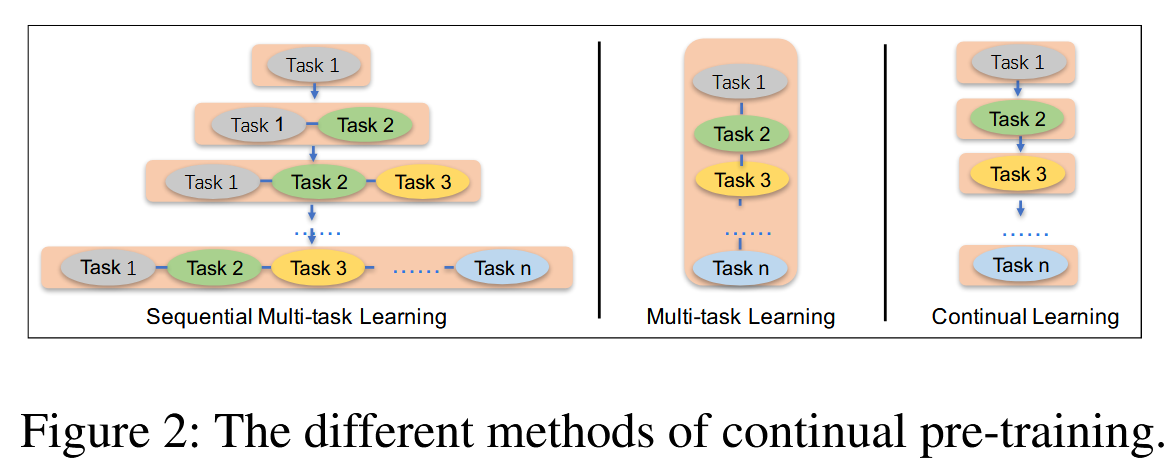
the difference among our method(continual multi-task learning), multitask learning from scratch and previous continual learning.
- Although multi-task learning from scratch could train multiple tasks at the same time, it is necessary that all customized pre-training tasks are prepared before the training could proceed.
- Traditional continual learning method trains the model with only one task at each stage with the demerit that it may forget the previously learned knowledge.
- the architecture of our continual multi-task learning in each stage contains a series of shared text encoding layers to encode contextual information,
ERNIE 2.0 Model
Model Structure
Transformer Encoder
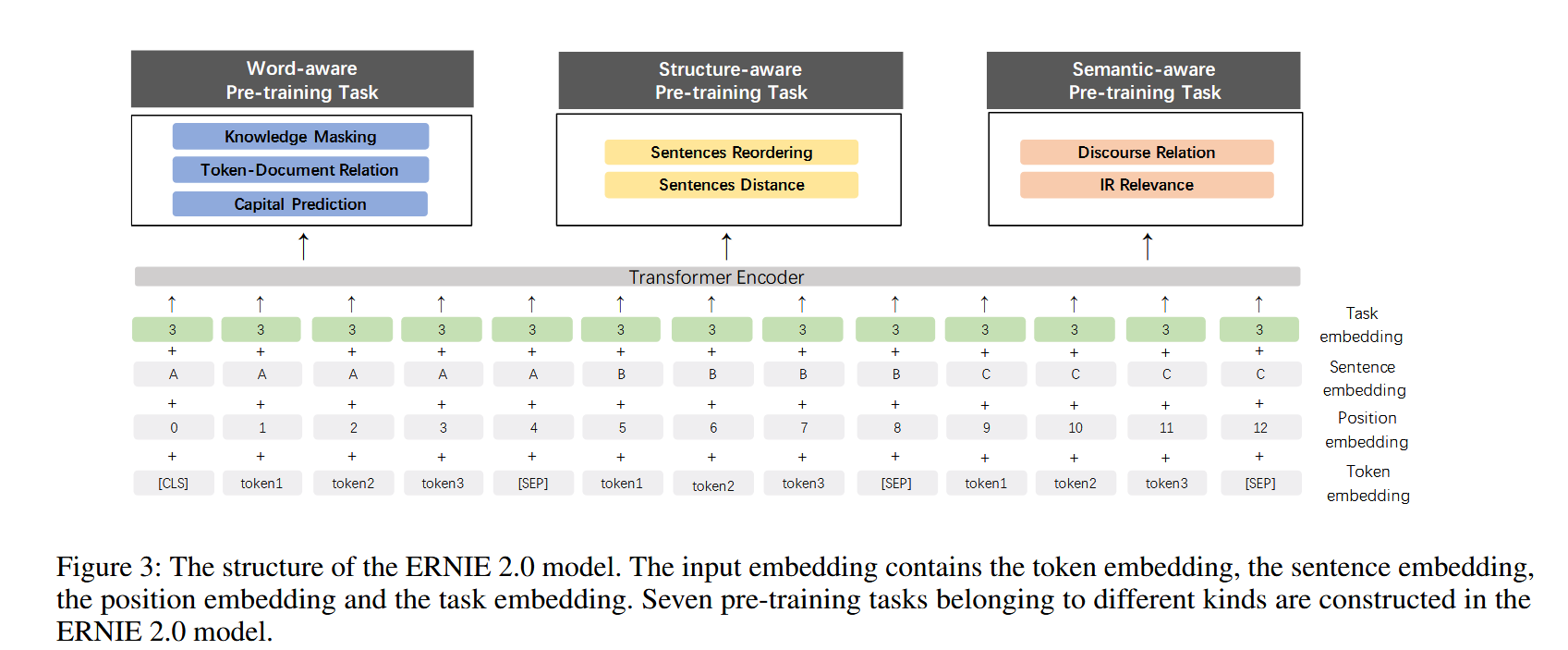
Task Embedding
The model feeds task embedding to represent the characteristic of different tasks. We represent different tasks with an id ranging from 0 to N. Each task id is assigned to one unique task embedding. The corresponding token, segment, position and task embedding are taken as the input of the model. We can use any task id to initialize our model in the fine-tuning process
实现参考ERNIE 的:什么是token type embedding?BERT 的Segment Embedding 是如何实现的
Pre-training Tasks
Word-aware Pre-training Tasks
Knowledge Masking Task
Similar to ERNIE: phrase masking and named entity masking
Capitalization Prediction Task:
Capitalized words usually have certain specific semantic information compared to other words in sentences. The cased model has some advantages in tasks like named entity recognition while the uncased model is more suitable for some other tasks. To combine the advantages of both models, we add a task to predict whether the word is capitalized or not
Token-Document Relation Prediction Task
This task predicts whether the token in a segment appears in other segments of the original document. Empirically, the words that appear in many parts of a document are usually commonly used words or relevant with the main topics of the document. Therefore, through identifying the frequently-occurring words of a document appearing in the segment, the task can enable the ability of a model to capture the key words of the document to some extent.
Structure-aware Pre-training Tasks
Sentence Reordering Task
This task aims to learn the relationships among sentences. During the pre-training process of this task, a given paragraph is randomly split into 1 to m segments and then all of the combinations are shuffled by a random permuted order. We let the pre-trained model to reorganize these permuted segments, modeled as a k-class classification problem where $k = \sum_{n=1}^{m} n!$. Empirically, the sentences reordering task can enable the pre-trained model to learn relationships among sentences in a document.
这个任务蛮有意思的,可以深入挖掘,应该an不仅仅能学习到句子之之间的关系,句子之间关系还隐含了逻辑推理,等任务
Sentence Distance Task
We also construct a pre-training task to learn the sentence distance using document-level information. This task is modeled as a 3-class classification problem. ”0” represents that the two sentences are adjacent in the same document, ”1” represent that the two sentences are in the same document, but not adjacent, and ”2” represents that the two sentences are from two different documents.
可以学习这个目标到具体任务之间的转化
Semantic-aware Pre-training Tasks、
Discourse Relation Task
we introduce a task to predict the semantic or rhetorical relation between two sentences. We use the
“预测两个句子之间的语义或修辞关系” 指的是:判断两个在上下文中相邻或相关的句子,在逻辑和功能上是如何连接在一起的。简单来说,就是回答一个问题:“第二句话相对于第一句话,起到了什么作用?”这不仅仅是看它们是否相关,而是要精确地定义它们之间是因果关系、对比关系、解释关系,还是其他类型的关系。
IR Relevance Task
We build a pre-training task to learn the short text relevance in information retrieval. It is a 3-class classification task which predicts the relationship between a query and a title. We take the query as the first sentence and the title as the second sentence. The search log data from a commercial search engine is used as our pre-training data. There are three kinds of labels in this task.
- The query and title pairs that are labelled as ” 0” stand for strong relevance, which means that the title is clicked by the users after they input the query.
- Those labelled as ”1” represent weak relevance, which implies that when the query is input by the users, these titles appear in the search results but failed to be clicked by users.
- The label ”2” means that the query and title are completely irrelevant and random in terms of semantic information.
这个任务很适合处理不同相似度的句子对之间的关系,可以适用于 到 标题到主评论、主评论到子评论
Experiments
ERNIE 2.0 is trained on 48 NVidia v100 GPU cards for the base model and 64 NVidia v100 GPU cards for the large model in both English and Chinese
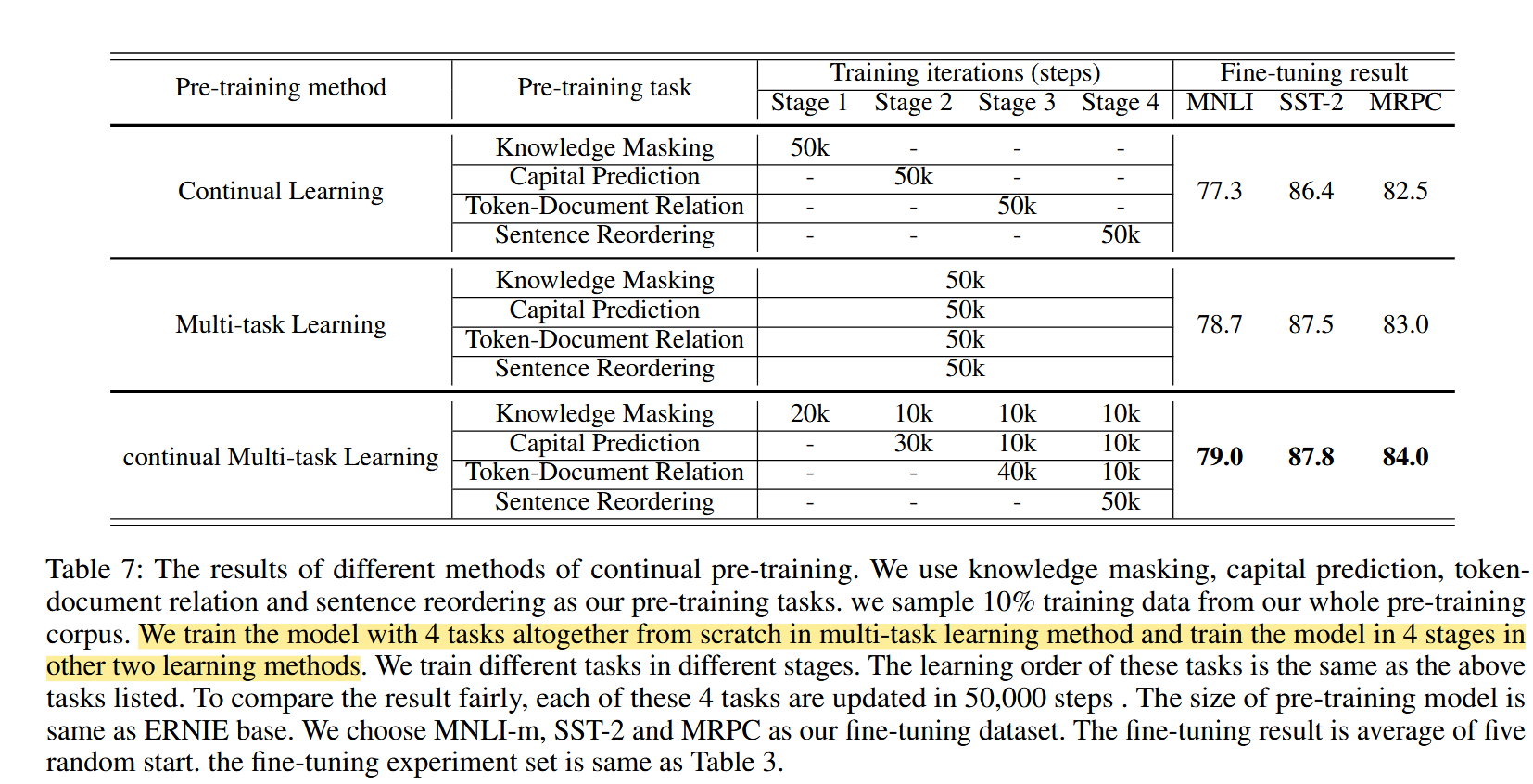
总结与分析
-
有些任务是蛮有趣的,但是任务特别多,有的可能不是特别有效,缺乏消融实验进一步说明这些任务中哪一种比较有效
-
这里对于不同任务的处理值得借鉴,直接在嵌入层用特定的id 编码词向量,然后像position embedding 一样和word embedding相加,就默认这是某任务的向量,具体实现细节需要进一步分析源代码
-
多个任务并行时,如何保证不遗忘知识,又能学到新任务的知识,又比较高效,是一个有意思的问题