文章来源
文章链接:[1904.09223] ERNIE: Enhanced Representation through Knowledge Integration
Introduction
Motivation
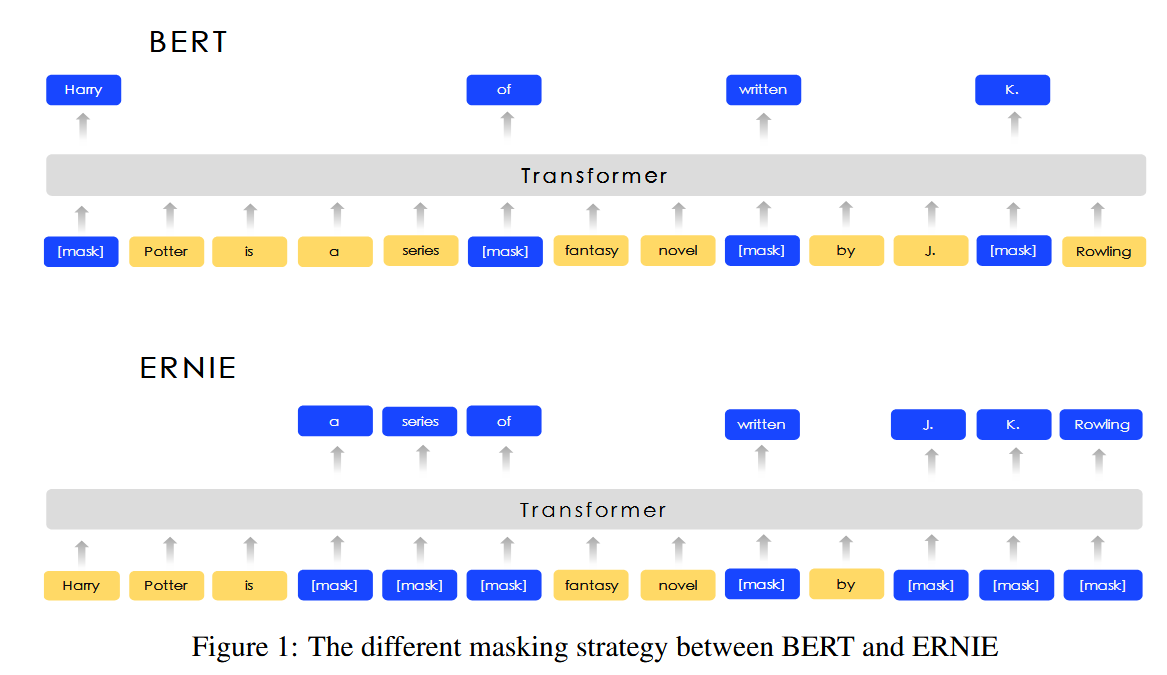
These works do not consider the prior knowledge in the sentence. For example, In the sentence ” Harry Potter is a series of fantasy novels written by J. K. Rowling”. Harry Potter is a novel name and J. K. Rowling is the writer. It is easy for the model to predict the missing word of the entity Harry Potter by word collocations inside this entity without the help of long contexts.
根据Harry 和 Potter 的共同出现关系,给出一个 能预测另一个
The model cannot predict Harry Potter according to the relationship between Harry Potter and J. K. Rowling. It is intuitive that if the model learns more about prior knowledge, the model can obtain more reliable language representation.
原来的BERT是会mask掉Potter 或者Rowling, 这样只能预测Potter 或者Rowling 而不是直接预测Harry Potter或者 J. K. Rowling
what is prior knowledge?
Objective
we propose a model called ERNIE (enhanced representation through knowledge integration) by using knowledge masking strategies. In addition to basic masking strategy, we use two kinds of knowledge strategies: phrase-level strategy and entity-level strategy. We take a phrase or a entity as one unit, which is usually composed of several words. All of the words in the same unit are masked during word representation training, instead of only one word or character being masked. In this way, the prior knowledge of phrases and entities are implicitly learned during the training procedure.
prior knowledge 是指这些phrases and entities 及其相互的关系,现在mask是以phrases 或者 entities 为单位,根据上下文来预测这些语义单位就能学习到知识
相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。示例如下:
Learnt by BERT :哈 [mask] 滨是 [mask] 龙江的省会,[mask] 际冰 [mask] 文化名城。 Learnt by ERNIE:[mask] [mask] [mask] 是黑龙江的省会,国际 [mask] [mask] 文化名城。
- 在 BERT 模型中,我们通过『哈』与『滨』的局部共现,即可判断出『尔』字,模型没有学习与『哈尔滨』相关的任何知识。
data
In order to reduce the training cost of the model, ERNIE is pre-trained on heterogeneous Chinese data, and then applied to 5 Chinese NLP tasks
Methods
Encoder
ERNIE use multi-layer Transformer (Vaswani et al., 2017) as basic encoder like previous pretraning model such as GPT, BERT and XLM
For Chinese corpus, we add spaces around every character in the CJK Unicode range and use the WordPiece (Wu et al., 2016) to tokenize Chinese sentences
Knowledge Integration
Instead of adding the knowledge embedding directly, we proposed a multi-stage knowledge masking strategy to integrate phrase and entity level knowledge into the Language representation.
what is multi-stage knowledge masking strategy?
这里的“分阶段”通常不是指严格的时间顺序(即先花1个月只训练基本掩码,再花1个月只训练短语掩码……)。
更准确的理解是:在同一个训练过程中,以混合、随机的方式,分阶段(类型)地应用不同的掩码策略。
具体来说:
- 数据批次混合: 在每一个训练批次中,模型接收到的数据样本,有些是采用了基本级掩码,有些是短语级掩码,有些是实体级掩码。
- 随机轮换: 对于每一个句子,模型会随机决定对其采用三种掩码策略中的哪一种。
- 统一训练: 无论采用哪种掩码策略,模型的权重都会根据同一个损失函数进行更新。
所以,这是一种 “训练策略上的分阶段(分类)” ,而不是 “训练时间上的分阶段” 。模型在整个训练过程中,始终同时接触和学习这三种不同难度的任务,从而最终获得同时涵盖基础语言学、概念组合和事实知识的强大语言表示能力。
Basic-Level Masking
similar to BERT
Because it is trained on a random mask of basic semantic units, high level semantic knowledge is hard to be fully modeled.
Phrase-Level Masking
Phrase is a small group of words or characters together acting as a conceptual unit. For English, we use lexical analysis and chunking tools to get the boundary of phrases in the sentences, and use some language dependent segmentation tools to get the word/phrase information in other language such as Chinese. In phrase-level mask stage, we also use basic language units as training input, unlike random basic units mask, this time we randomly select a few phrases in the sentence, mask and predict all the basic units in the same phrase.
Entity-Level Masking
As in the phrase masking stage, we first analyze the named entities in a sentence, and then mask and predict all slots in the entities.

Experiment
Data
we draw the mixed corpus Chinese Wikepedia, Baidu Baike, Baidu news and Baidu Tieba. The number of sentences are 21M, 51M, 47M, 54M. respectively. Baidu Baike contains encyclopedia articles written in formal languages, which is used as a strong basis for language modeling. Baidu news provides the latest information about movie names, actor names, football team names, etc. Baidu Tieba is an open discussion forum like Reddits, where each post can be regarded as a dialogue thread. Tieba corpus is used in our DLM task, which will be discussed in the next section. We perform traditional-to-simplified conversion on the Chinese characters, and upper-to-lower conversion on English letters. We use a shared vocabulary of 17,964 unicode characters for our model.
what is unicode characters?
DLM (Dialogue Language Model)
Dialogue data is important for semantic representation, since the corresponding query semantics of the same replies are often similar. ERNIE models the Query-Response dialogue structure on the DLM (Dialogue Language Model) task. As shown in figure 3, our method introduces dialogue embedding to identify the roles in the dialogue. ERNIE’s Dialogue embedding plays the same roles as token type embedding in BERT, except that ERNIE can also represent multi-turn conversations (e.g. QRQ, QRR, QQR, where Q and R stands for ”Query” and ”Response” respectively). Like MLM in BERT, masks are applied to enforce the model to predict missing words conditioned on both query and response. What’s more, we generate fake samples by replacing the query or the response with a randomly selected sentence. The model is designed to judge whether the multi-turn conversation is real or fake
这个和最初的BERT的Predict Next Sentence好像也没有区别啊,就是换了个名,所以它的损失函数是不是没有NSP任务?
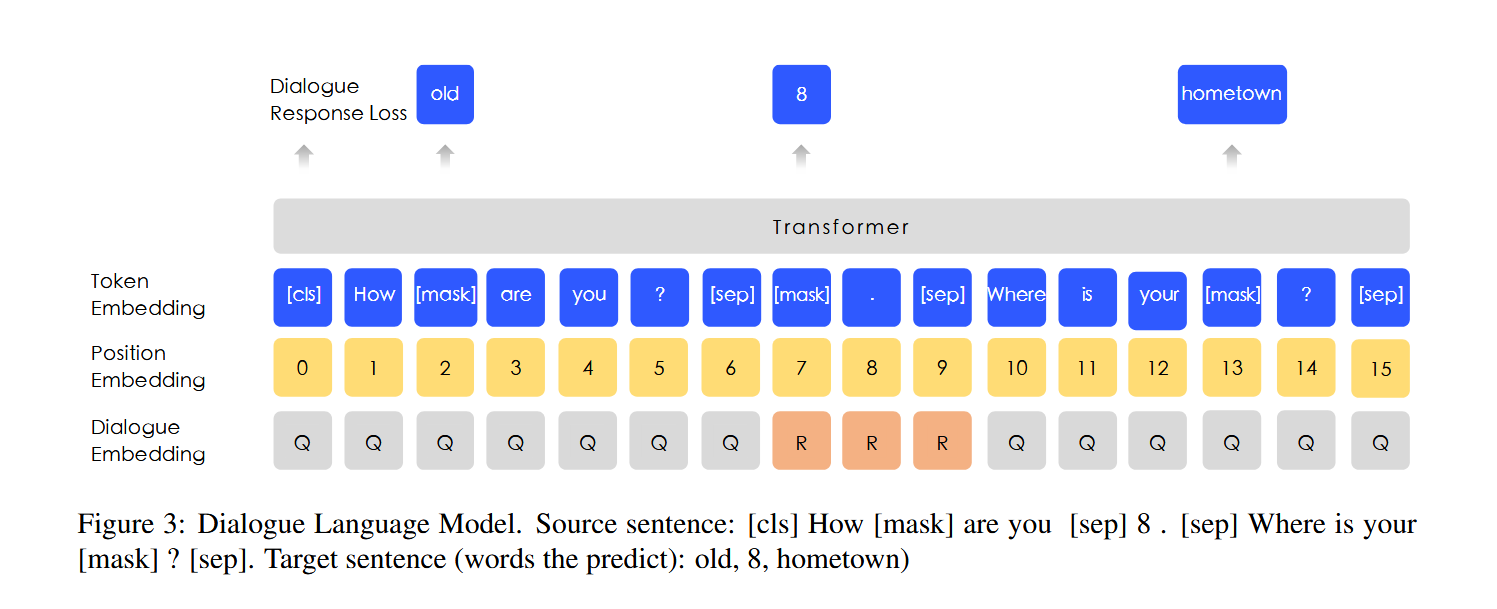
什么是token type embedding?BERT 的Segment Embedding 是如何实现的
首先,要理解Segment Embedding的设计目的:为了区分输入中的多个句子。BERT的关键预训练任务之一是“下一句预测”,它需要模型理解两个句子之间的关系。Segment Embedding就是用来告诉模型:“哪些token属于句子A,哪些属于句子B。”
具体实现步骤
1. 输入格式
BERT的输入通常由两个句子拼接而成,格式如下:
[CLS] 第一个句子的 tokens [SEP] 第二个句子的 tokens [SEP]
[CLS]:位于开头,用于分类任务。[SEP]:特殊分隔符,用于分隔句子和表示结束。2. 创建Segment IDs
在将文本转换成token ID序列后,我们会并行地创建一个Segment ID序列(也叫做Token Type ID序列)。这个序列的长度与token ID序列完全一致。
- 对于第一个句子的所有token(包括开头的
[CLS]和第一个[SEP]),它们的Segment ID都被赋值为 0。- 对于第二个句子的所有token(包括第二个
[SEP]),它们的Segment ID都被赋值为 1。举个例子: 假设我们有两个句子:
- 句子A: “我喜欢机器学习”
- 句子B: “它很有趣”
那么输入序列和对应的Segment ID序列如下:
Token [CLS] 我 喜欢 机器 学习 [SEP] 它 很 有趣 [SEP] Segment ID 0 0 0 0 0 0 1 1 1 1 特殊情况:单句输入 当输入只有一个句子时,所有token(包括
[CLS]和[SEP])的Segment ID都是0。3. 嵌入层
创建好Segment ID序列(例如
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1])之后,这个序列会被送入一个Segment Embedding层。
- 这个嵌入层本质上是一个查找表,其大小是
[2, hidden_size]。
2:因为只有两种可能的Segment ID(0和1)。hidden_size:BERT模型的隐藏层维度(例如768维)。- 通过这个查找表,每个Segment ID(0或1)都被映射为一个密集的、可训练的向量(即Segment Embedding)。
4. 合成最终输入向量
BERT的最终输入表示是三种嵌入的逐元素相加:
- Token Embeddings:词嵌入,来自WordPiece分词器。
- Segment Embeddings:段落嵌入,就是我们上面详细描述的部分。
- Position Embeddings:位置嵌入,表示每个token在序列中的位置。
用公式表示就是:
Final_Embedding = Token_Embedding + Segment_Embedding + Position_Embedding这个合成的最终向量才是被送入BERTTransformer编码器的输入。
##
下游任务的表现
Experiments on Chinese NLP Tasks ERNIE is applied to 5 Chinese NLP tasks, including natural language inference, semantic similarity, named entity recognition, sentiment analysis, and question answering.
还上了一个完型填空,这个倒是蛮适合用来做可解释分析的
总结
对于QA对的匹配关系利用明显不足
多轮对话的建模倒是蛮适合深度挖掘的