论文:[1907.11692] RoBERTa: A Robustly Optimized BERT Pretraining Approach
Introduction
Motivation: Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication study of BERT pretraining (Devlin et al., 2019), which includes a careful evaluation of the effects of hyperparmeter tuning and training set size
We find that BERT was significantly undertrained and propose an improved recipe for training BERT models, which we call RoBERTa, that can match or exceed the performance of all of the post-BERT methods. Our modifications are simple, they include: (1) training the model longer, with bigger batches, over more data; (2) removing the next sentence prediction objective; (3) training on longer sequences; and (4) dynamically changing the masking pattern applied to the training data.
contributions:
1) We present a set of important BERT design choices and training strategies and introduce We leave this exploration to future work. alternatives that lead to better downstream task performance; (2) We use a novel dataset, CCNEWS, and confirm that using more data for pretraining further improves performance on downstream tasks;
Our training improvements show that masked language model pretraining, under the right design choices, is competitive with all other recently published methods
Background:a brief overview of BERT
Setup
BERT takes as input a concatenation of two segments (sequences of tokens), $ x_1, . . . , x_N $ and $ y_1, . . . , y_M $ . Segments usually consist of more than one natural sentence. The two segments are presented as a single input sequence to BERT with special tokens delimiting them: $ [CLS ], x_1, . . . , x_N , [SEP ], y_1, . . . , y_M , [EOS] $. M and N are constrained such that M + N < T , where T is a parameter that controls the maximum sequence length during training
training objectives
Mask
Masked Language Model (MLM) A random sample of the tokens in the input sequence is selected and replaced with the special token [MASK ]. The MLM objective is a cross-entropy loss on predicting the masked tokens. BERT uniformly selects 15% of the input tokens for possible replacement. Of the selected tokens, 80% are replaced with [MASK ], 10% are left unchanged, and 10% are replaced by a randomly selected vocabulary token.
工程实践,在一开始就全部处理好mask 而不是在运行的时候才去做mask,提升效率:In the original implementation, random masking and replacement is performed once in the beginning and saved for the duration of training, although in practice
Next Sentence Prediction (NSP)
NSP is a binary classification loss for predicting whether two segments follow each other in the original text. Positive examples are created by taking consecutive sentences from the text corpus. Negative examples are created by pairing segments from different documents. Positive and negative examples are sampled with equal probability.
BERT的结构:引用了别人的图,有点找不到是那篇文档了
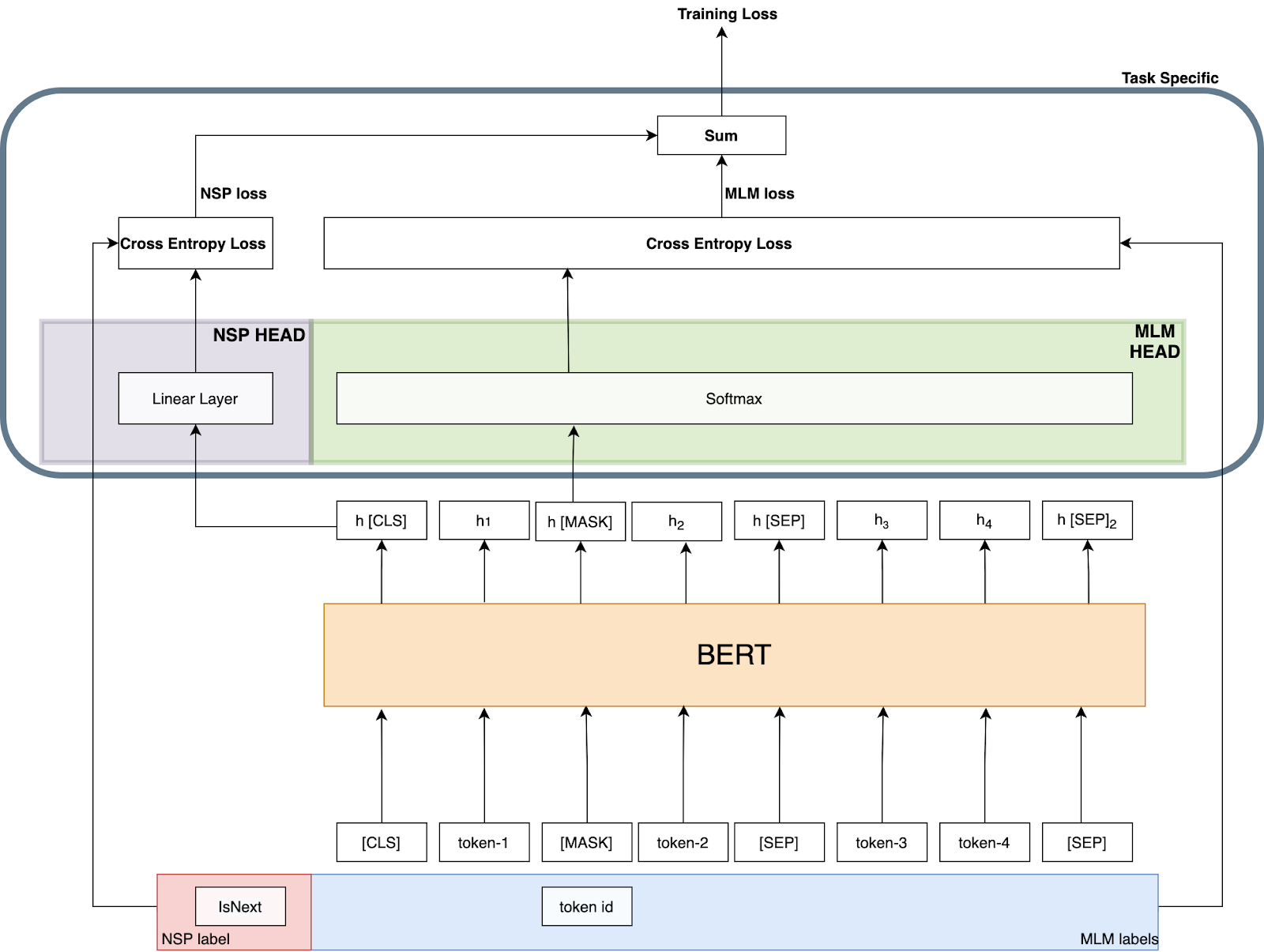
Experiments
训练策略
We pretrain with sequences of at most T = 512 tokens. Unlike Devlin et al. (2019), we do not randomly inject short sequences, and we do not train with a reduced sequence length for the first 90% of updates. We train only with full-length sequences
1. “We pretrain with sequences of at most T = 512 tokens.”
- 意思: 在预训练时,我们喂给模型的每一个训练样本(序列)的最大长度是512个词元(token)。这是BERT等模型常用的一个标准长度。
- 背景: 处理长序列需要更多的计算资源(GPU内存等),所以通常会设置一个上限。
2. “Unlike Devlin et al. (2019), we do not randomly inject short sequences, and we do not train with a reduced sequence length for the first 90% of updates.”
-
这是在对比BERT原始论文中的两种训练技巧:
a) 不随机注入短序列:
- BERT的做法: 在准备训练数据时,并不是所有序列都填充到512长度。他们会以10%的概率使用短于512的序列(例如,长度只有128)。这是一种正则化手段,可能为了让模型不过度依赖长距离上下文,同时也能够加快训练速度(因为处理短序列更快)。
- 本文的做法: 我们不这样做。我们所有的序列都是(通过填充或截断)处理成固定长度。
b) 不在前90%的训练步数中使用缩短的序列长度:
- BERT的做法: 在训练的最初90%的步骤里,他们使用较短的序列(比如128)进行训练,只在最后10%的训练步骤中才使用完整的512长度序列。
- 这样做的目的: 主要为了加速训练。在训练初期,模型参数还很随机,用短序列训练可以:
- 显著减少计算量,让每次迭代更快。
- 在相同时间内完成更多次参数更新。
- 等到模型对任务有了一定的理解后,再用长序列进行“精调”,学习长距离依赖关系。
- 本文的做法: 我们不这样做。我们从第一步开始就使用完整的512长度序列进行训练。
3. “We train only with full-length sequences”
- 意思: 这是对前面两点的总结。我们的训练策略非常“纯粹”和“强硬”:在整个预训练过程中,每一个批次(batch)中的每一个序列,都是完整的512长度。
为什么要这么做?可能的原因
作者选择这种策略,可能基于以下考虑:
- 训练过程的简单性: 避免了管理两种不同序列长度策略的复杂性。训练流程更简洁,更容易复现。
- 一致性的优化: 模型从始至终都在学习如何处理相同长度的输入,优化过程可能更加稳定和一致。避免了因序列长度突然变化(从128跳到512)而可能产生的优化震荡。
- 性能考量: 作者可能通过实验发现,对于他们的模型和任务,从一开始就使用全长度序列训练能带来更好的最终性能。虽然前期训练慢一些,但模型能更早、更持续地学习长距离依赖关系,这可能比训练速度更重要。
- 计算资源充足: 可能作者拥有足够的计算资源(例如更强大的GPU集群),因此可以承受从一开始就用全长序列训练所带来的计算成本。
Machines: We train with mixed precision floating point arithmetic on DGX-1 machines, each with 8 × 32GB Nvidia V100 GPUs interconnected by Infiniband
data
We consider five English-language corpora of varying sizes and domains, totaling over 160GB of uncompressed text. 从BERT本身的16G扩大了10倍
Training Procedure Analysis
不同的mask策略:Static vs. Dynamic Masking
The original BERT implementation performed masking once during data preprocessing, resulting in a single static mask. To avoid using the same mask for each training instance in every epoch, training data was duplicated 10 times so that each sequence is masked in 10 different ways over the 40 epochs of training. Thus, each training sequence was seen with the same mask four times during training
We find that our reimplementation with static masking performs similar to the original BERT model, and dynamic masking is comparable or slightly better than static masking
NSP任务对比
AB是两个不同的documents, 序号表示document内的句子顺序
| 格式类型 | 组成单元 | 是否跨文档 | NSP损失 | 输入示例 | 关键特点 |
|---|---|---|---|---|---|
| SEGMENT-PAIR+NSP | 两个多句片段 | ✅ | ✅ | [CLS] A1 A2 [SEP] A3 A4 [SEP] NSP: IsNext [CLS] A3 A4 [SEP] B1 B2 [SEP] NSP: NotNext |
• 每个输入包含两个文本片段 • 片段可能来自不同文档 • 保留下一句预测任务 |
| SENTENCE-PAIR+NSP | 两个单句 | ✅ | ✅ | [CLS] A2 [SEP] A3 [SEP] NSP: IsNext [CLS] A4 [SEP] B1 [SEP] NSP: NotNext |
• 每个输入只有两个句子 • 输入长度很短 • 需增大batch size |
| FULL-SENTENCES | 连续句子流 | ✅ | ❌ | [CLS] A1 A2 A3 A4 [DOC] B1 B2 B3 [SEP] |
• 连续拼接完整句子 • 可跨文档边界 • 移除NSP损失 |
| DOC-SENTENCES | 连续句子流 | ❌ | ❌ | 样本1: [CLS] A1 A2 A3 A4 [SEP] 样本2: [CLS] B1 B2 B3 B4 [SEP] |
• 仅限单文档内句子 • 输入长度可变 • 动态调整batch size |
| 对比维度 | 实验设计 | 逻辑合理性 |
|---|---|---|
| 片段长度 | SENTENCE-PAIR(极短) vs SEGMENT-PAIR(中等) vs FULL-SENTENCES(全长) | ✅ 完美控制了”上下文长度”这个关键变量 |
| 文档边界 | FULL-SENTENCES(可跨文档) vs DOC-SENTENCES(不跨文档) | ✅ 分离了”跨文档影响”这个因素 |
| NSP任务 | 前两种(有NSP) vs 后两种(无NSP) | ✅ 直接测试NSP任务的有效性 |
| 训练效率 | 通过调整batch size保持总token数一致 | ✅ 确保比较的公平性,排除计算量差异 |
第一层对比:SEGMENT-PAIR+NSP vs SENTENCE-PAIR+NSP
- 测试:在都有NSP的情况下,片段长度的影响
- 预期:如果SENTENCE-PAIR效果差,说明长上下文很重要
第二层对比:SEGMENT-PAIR+NSP vs FULL-SENTENCES
- 测试:在都有长上下文的情况下,NSP任务的影响
- 关键:唯一变量就是NSP任务的存在与否
第三层对比:FULL-SENTENCES vs DOC-SENTENCES
- 测试:在都无NSP的情况下,跨文档的影响
- 预期:如果效果相近,说明跨文档不是关键因素
结果
| 对比组 | 性能表现 | 关键结论 | 原因分析 |
|---|---|---|---|
| SEGMENT-PAIR+NSP vs SENTENCE-PAIR+NSP | SEGMENT-PAIR > SENTENCE-PAIR | ❌ 单句子训练效果差 | 无法学习长距离依赖关系 |
| DOC-SENTENCES vs BERT原始结果 | DOC-SENTENCES > BERTBASE | ✅ 单文档块训练更优 | 移除NSP损失有益 |
| DOC-SENTENCES vs FULL-SENTENCES | DOC-SENTENCES ≈ FULL-SENTENCES (略优) | ⚖️ 单文档稍好但差异小 | 文档内连续性更重要 |
- 否定NSP:证明下一句预测不是必要的预训练任务
- 强调连续性:文档内的连续文本比人工构造的片段对更有效
- 重新定义输入:应该使用自然连续的文本块而非刻意分割的片段
However, because the DOC-SENTENCES format results in variable batch sizes, we use FULLSENTENCES in the remainder of our experiments for easier comparison with related work
不同的Batch size
We observe that training with large batches improves perplexity for the masked language modeling objective, as well as end-task accuracy. Large batches are also easier to parallelize via distributed data parallel training.
Text Encoding:如何编码词
Byte-Pair Encoding (BPE) (Sennrich et al., 2016) is a hybrid between character- and word-level representations that allows handling the large vocabularies common in natural language corpora. Instead of full words, BPE relies on subwords units, which are extracted by performing statistical analysis of the training corpus.
Early experiments revealed only slight differences between these encodings, with the Radford et al. (2019) BPE achieving slightly worse end-task performance on some tasks. Nevertheless, we believe the advantages of a universal encoding scheme outweighs the minor degredation in performance and use this encoding in the remainder of our experiments. A more detailed comparison of these encodings is left to future work.
RoBERTA
In the previous section we propose modifications to the BERT pretraining procedure that improve end-task performance. We now aggregate these improvements and evaluate their combined impact. We call this configuration RoBERTa for Robustly optimized BERT approach. Specifically, RoBERTa is trained with dynamic masking (Section 4.1), FULL-SENTENCES without NSP loss (Section 4.2), large mini-batches (Section 4.3) and a larger byte-level BPE (Section 4.4).